LibraryHippo 2020 - Scraping Library Websites
Now that the toy LibraryHippo on Heroku is sending periodic e-mails, it's time to provide it with meaningful content to send, by having it scrape a library's website. This should be relatively straightforward, but there's some risk as it's not an operation covered in The Flask Mega-Tutorial.
The production application gathers information from libraries using a combination of App Engine's custom URL Fetch service, an older version of the Beautiful Soup HTML parser (which had to be copied into the application source), and some glue that I wrote. Today I'll try to replicate that using modern, commodity components.
Gathering requirements
I've heard that the Requests library is a feature-rich and popular library for sending HTTP requests. Knowing no more than that, I'll try it. Beautiful Soup has worked very well for me in the past, but has had a number of significant releases since the version I've used, so I'll try the latest, 4.8.2 as I write.
pip install requests
pip install BeautifulSoup4
inv freezeLibrary Credential Management
Library websites don't allow unfettered access to their patrons' records, thank
goodness, so it'll be necessary to use at least one patron's credentials during
the "scraping" test. I don't want to embed my credentials in the application
source code, so they have to be stored somewhere else. Had I already integrated
a permanent datastore and implement user management, the credentials would be
tied to the LibraryHippo user's account, but for now I'll read them from
environment variables that I'll save in the secrets file established in
Sending Email from Heroku.
# secrets
# …
PATRON_NAME=Blair Conrad
CARD_NUMBER=123456789
PIN=9876with the corresponding change to the Config.
Implementation
When a patron wants to check their library card status at the Waterloo Public Library, they have to visit the login page and provide their credentials, after which they are taken to a summary page that basically just show the number of checkouts and held items, with links to complete lists of their checkouts and holds. That's 4 pages visited, and possibly some hidden redirects, plus one if they manually logout. I planned to have the automated components follow the same path.
Login
My initial thought was that LibraryHippo could login directly, just by posting credentials to the website, but it failed miserably. The reason: hidden fields. The login page looks like it has 4 inputs, counting the "Submit" button as an input:
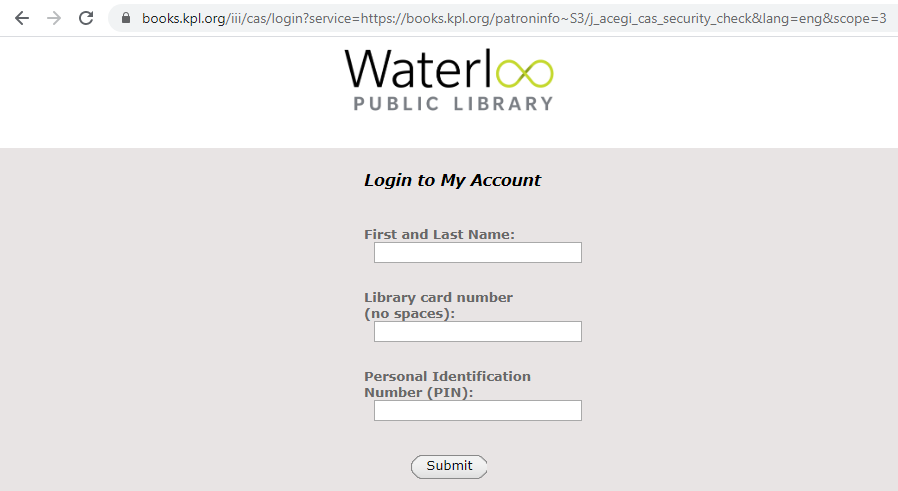
But there are actually 6. The four we see and two hidden ones, called lt and _eventId:
<input id="name" name="name" type="text" value="" size="25" maxlength="50" tabindex="15">
<input id="code" name="code" type="text" value="" size="25" maxlength="50" tabindex="20">
<input id="pin" name="pin" type="password" value="" size="25" maxlength="64" tabindex="30">
<input type="submit" name="Log In" class="loginSubmit" tabindex="35">
<input type="hidden" name="lt" value="_cB2859561-37E4-542A-1165-9B73858A095A_k57C7CE2E-6774-24D9-E8F6-3A54E706F248" />
<input type="hidden" name="_eventId" value="submit" />When I submit the form without them, the login fails. The lt field's value
is different every time I visit the login page, so I assume the server is using
it as a session identifier or some such. The only way to have a successful login
is to harvest that value from the login page. So the card-checking flow must be:
- request the login page
- find the hidden form fields
- submit the login form, including the configured credentials as well as the hidden field values
- read the response and find the links to the checkouts and holds pages
- request the checkouts page and read the results
- request the holds page and read the results
- request the logout page, to logout
The first 3 steps are covered by the login method on my new WPL class:
# app/libraries/wpl.py
from bs4 import BeautifulSoup
from requests import Session
class WPL:
def login_url(self):
return (
"https://books.kpl.org/iii/cas/login?service="
+ "https://books.kpl.org/patroninfo~S3/j_acegi_cas_security_check&lang=eng&scope=3"
)
def check_card(self, patron, number, pin):
session = Session()
summary_page = self.login(session, patron, number, pin)
# …
def login(self, session, patron, number, pin):
initial_login_page_view = session.get(self.login_url())
login_page = BeautifulSoup(initial_login_page_view.text, "html.parser")
form_fields = self.get_form_fields(login_page)
form_fields.update({"name": patron, "code": number, "pin": pin})
login_response = session.post(self.login_url(), form_fields)
return BeautifulSoup(login_response.text, "html.parser")
def get_form_fields(self, page):
form_fields = {}
for input_field in page.find_all("input"):
if input_field["type"] == "submit":
form_fields["submit"] = input_field["name"]
else:
form_fields[input_field["name"]] = input_field.get("value", "")
return form_fieldsStarting from the top, there are a few things to note:
- I import key classes from Beautiful Soup (
bs4) and the Requests library - The login URL is hard-coded here. You have to start somewhere.
- I'm passing
patron,number, andpininto thecheck_cardmethod, which is the principal entry point into this class check_cardimmediately creates arequests.Sessionobject to communicate with the outside world. It's possible to call methods likegetandpostdirectly on therequestsmodule, but the Session class provides session management by tracking cookies, pools connections, and can persist parameters across requests. Use of theSessionclass is the key to having the library website grant access on subsequent requests. Under Google App Engine, I had to write request decorators to handle the cookies and session managementloginfirst requests the login page as discussed, and parses it using Beautiful Soup before passing toget_form_fieldsto find all the hidden and special (e.g. "submit") fields to ensure the right values are posted. Not how easy thefind_allmethod makes it to locate all the input fields.loginthen fills in values specific to this card: patron name, card number ("code") and PIN, beforepost\ ing the result and returning it tocheck_cardfor future processing
Finding the checkouts and holds pages
Once a user logs into the WPL, they see a summary page that contains rather a lot of personal information that they probably don't care to see every day, as well as some links that would allow them to update their account and, most importantly, a link to their holds and one to their checkouts, right at the bottom of the box above the "Log Out" button.
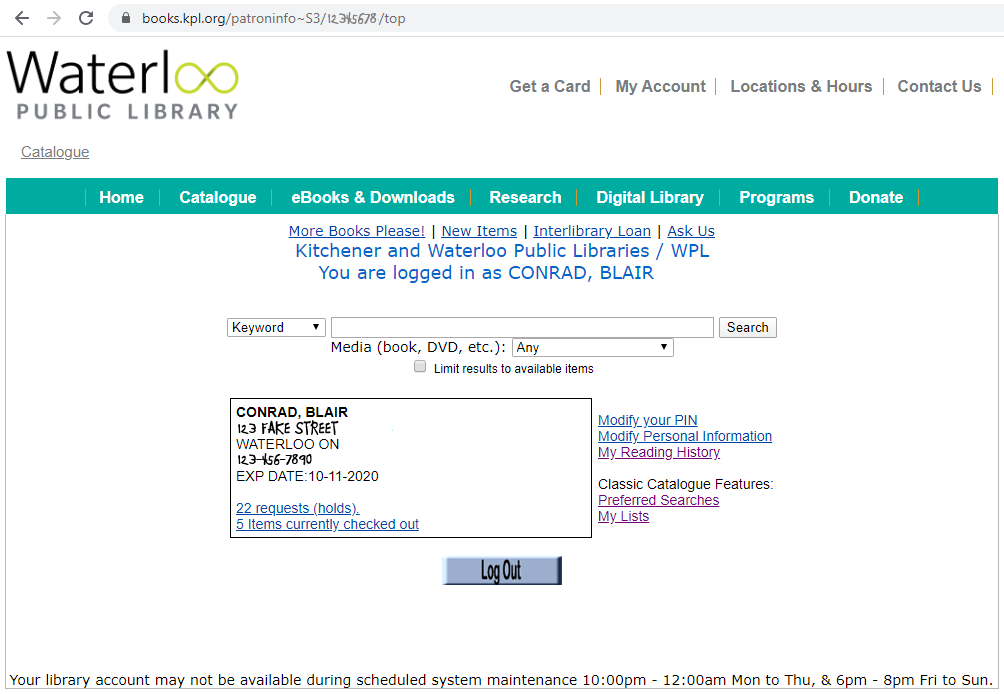
It's those last two that we'll be going after. Unfortunately, the links aren't clearly marked with an ID or even a class:
<div class="patNameAddress">
<strong>CONRAD, BLAIR</strong><br>
123 FAKE STREET<br>
WATERLOO ON<br>
132-456-7890<br>
EXP DATE:10-11-2020<br>
<br>
<div>
</div>
<div>
<a href="/patroninfo~S3/12345678/holds" target="_self">22 requests (holds).</a>
</div>
<div>
<a href="/patroninfo~S3/12345678/items" target="_self">5 Items currently checked out</a>
</div>
</div>The URLs vary from patron to patron, so we can't hard-code them. I'll cheat a little and look for links that end in "/holds" or "/items":
# app/libraries/wpl.py
import re
import urllib.parse
# …
class WPL:
def check_card(self, patron, number, pin):
session = Session()
summary_page = self.login(session, patron, number, pin)
holds_url = urllib.parse.urljoin(
self.login_url(),
summary_page.find(name="a", href=re.compile("/holds$"))["href"],
)
items_url = urllib.parse.urljoin(
self.login_url(),
summary_page.find(name="a", href=re.compile("/items$"))["href"],
)
# …Beautiful Soup looks on the summary page for <a> tags whose href match
the supplied regular expressions ("ends with /holds" or "ends with /items") and
returns the results. Indexing by "href" returns that attribute's value.
Since the URLs were relative, I join them to the original login URL to getd
absolute URLs.
Loading the Holds
The hold page repeats the same personal information from the summary page, and then lists all the patron's holds in a table.
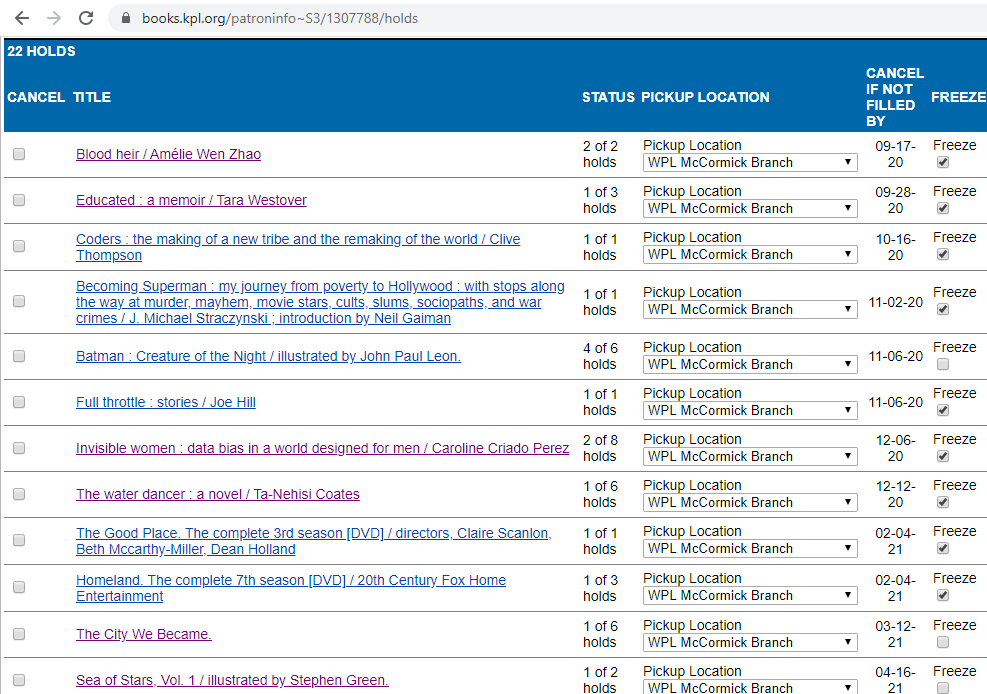
And the HTML behind the table starts like this:
<table lang="en" class="patFunc">
<tr class="patFuncTitle">
<th colspan="6" class="patFuncTitle">
<label id="items_count">22 HOLDS</label>
</th>
</tr>
<tr class="patFuncHeaders">
<th class="patFuncHeaders"> CANCEL </th>
<th class="patFuncHeaders"> TITLE </th>
<th class="patFuncHeaders"> STATUS </th>
<th class="patFuncHeaders">PICKUP LOCATION</th>
<th class="patFuncHeaders"> CANCEL IF NOT FILLED BY </th>
<th class="patFuncHeaders"> FREEZE </th>
</tr>
<tr class="patFuncEntry on_ice">
<td class="patFuncMark" >
<input type="checkbox" name="cancelb2677337x00" id="cancelb2677337x00" />
</td>
<td class="patFuncTitle">
<label for="cancelb2677337x00">
<a href="/record=b2677337~S3">
<span class="patFuncTitleMain">Blood heir / Amélie Wen Zhao</span>
</a>
</label>
<br />
</td>
<td class="patFuncStatus"> 2 of 2 holds </td>
<td class="patFuncPickup">
<div class="patFuncPickupLabel">
<label for="locb2677337x00">Pickup Location</label>
</div>
<select name=locb2677337x00 id=locb2677337x00 >
<option value="mn+++" >Central Library-KPL</option>
<option value="ch+++" >Country Hills Library-KPL</option>
<option value="fh+++" >Forest Heights Library-KPL</option>
<option value="gr+++" >Grand River Stanley Pk Lib-KPL</option>
<option value="pp+++" >Pioneer Park Library-KPL</option>
<option value="w++++" >WPL Main Library</option>
<option value="wm " selected="selected">WPL McCormick Branch</option>
<option value="ww+++" >WPL John M. Harper Branch</option>
</select>
</td>
<td class="patFuncCancel">09-17-20</td>
<td class="patFuncFreeze" >
<div class="patFuncFreezeLabel">
<label for="freezeb2677337x00" >Freeze</label>
</div>
<input type="checkbox" name="freezeb2677337x00" checked />
</td>
</tr>Each significant cell in the table has a class indicator that can be used to
interpret the contents. Note that since the table is actually part of a form,
where the patron can choose to cancel, freeze, or change the pickup location of
an item, some td elements contain input controls, slightly complicating the
parsing. Still, it's not that difficult to extract the information:
# app/libraries/wpl.py
def get_holds(self, session, holds_url):
holds = []
holds_page = BeautifulSoup(session.get(holds_url).text, "html.parser")
holds_table = holds_page.find("table", class_="patFunc")
for hold_row in holds_table.children:
if hold_row.name != "tr" or "patFuncEntry" not in hold_row["class"]:
continue
hold = {}
for hold_cell in hold_row.children:
if hold_cell.name != "td":
continue
cell_class = hold_cell["class"][0]
cell_name = cell_class.replace("patFunc", "")
if cell_name == "Mark":
continue
if cell_name == "Pickup":
hold[cell_name] = hold_cell.find(
"option", selected="selected"
).string
elif cell_name == "Freeze":
hold[cell_name] = "checked" in hold_cell.input.attrs
else:
# logger.info("cell " + cell_name)
hold[cell_name] = "".join(hold_cell.strings)
holds.append(hold)
return holds
# …
def check_card(self, patron, number, pin):
# …
result = "<h1>Holds</h1>"
for hold in self.get_holds(session, holds_url):
result += "<dl>"
for k, v in hold.items():
result += f"<dt>{k}</dt><dd>{v}</dd>"
result += "</dl><hr>"
return resultI load the page, find the table, and iterate over rows with the patFunEntry
class, extracting values to shove in a hold object, which is just a dictionary.
the default action is to store the contents of the td, but the "Mark" column
is just used to cancel holds, and conveys no information, so I drop it. The
"Pickup" column always contains a number of selections, so I'm carful to grab
the option element that is "selected". Finally the "Freeze" column is
effectively a boolean: if the input has a "checked" attribute, the hold is
frozen.
Back in check_card, I just loop over the holds, printing a dl for each
one, listing the attributes. It's not pretty, and would be better as a Jinja
template, but it's good enough for a proof of concept.
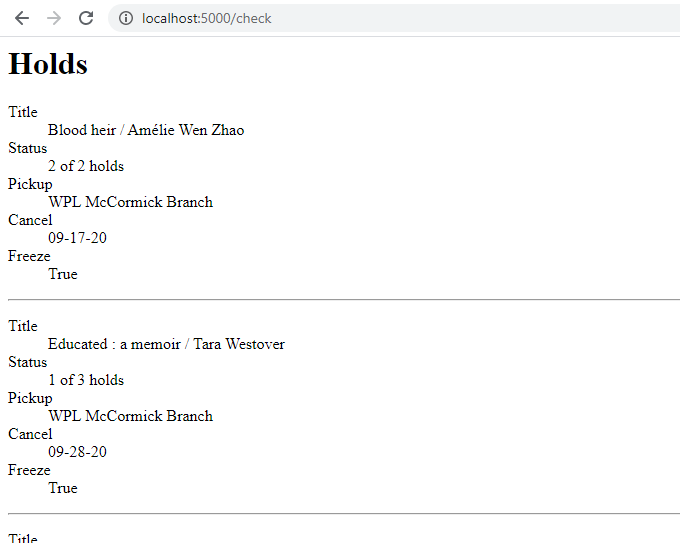
Loading the Checkouts
Parsing the Checkouts was to have been the same as parsing the holds, so I was
going to omit it, but that plan fell through when I found that the checkouts
page's HTML is malformed in a way that defeated the html.parser library.
Some tr tags aren't closed in the table:
<table lang="en" class="patFunc">
<tr class="patFuncTitle">
<th colspan="5" class="patFuncTitle">5 ITEMS CHECKED OUT</th>
</tr>
<tr class="patFuncHeaders">
<th class="patFuncHeaders"> RENEW </th>
<th class="patFuncHeaders"> TITLE </th>
<th class="patFuncHeaders"> BARCODE </th>
<th class="patFuncHeaders"> STATUS </th>
<th class="patFuncHeaders"> CALL NUMBER </th>
<!-- NO CLOSING TR -->
<tr class="patFuncEntry">
<td class="patFuncMark"><input type="checkbox" name="renew0" id="renew0" value="i3879884" /></td>
<td class="patFuncTitle"><label for="renew0"><a href="/record=b2529260~S3"><span class="patFuncTitleMain">Banff, Jasper & Glacier National Parks</span></a></label><br /></td>
<td class="patFuncBarcode"> 33420013067559 </td>
<td class="patFuncStatus"> DUE 03-02-20 <span class="patFuncRenewCount">Renewed 1 time</span></td>
<td style="text-align:left" class="patFuncCallNo"> 917.1233204 Ban </td>
</tr>As a result, Beautiful Soup saw only the "patFuncTitle" and "patFuncHeaders" rows. The workaround is to install the lxml XML and HTML parser and have BeautifulSoup use it:
pip install lxml
inv freeze# app/libraries/wpl.py
def get_checkouts(self, session, checkouts_url):
checkouts = []
checkouts_page = BeautifulSoup(session.get(checkouts_url).text, "lxml")
# fairly boring parsing hereafterDeploying to Heroku
Deploying is straightforward. I use my fancy inv deploy command and set the new secret environment variables:
heroku config:set "PATRON_NAME=Blair Conrad"
heroku config:set CARD_NUMBER=123456789
heroku config:set PIN=9876And voila:
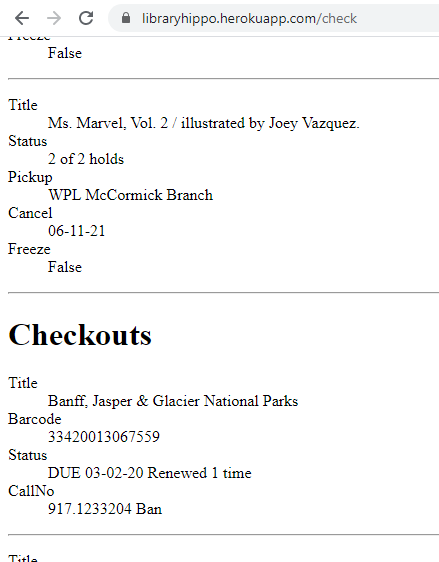
Progress
Four of nine requirements have been met!
| requirement | |
|---|---|
| ✓ | web app hosting |
| ✓ | scheduled jobs (run in UTC) |
| ✓ | scraping library websites on users' behalf |
| next | small persistent datastore |
| social authentication | |
| ✓ | sending e-mail |
| nearly free | |
| job queues | |
| custom domain name |